【Rails】Gem "rails-admin"を使用して、管理画面を作成する流れ
はじめに
Ruby on Railsでクイズアプリを作っている。管理画面でクイズの問題と回答が追加できる機能を実装するために、Gem "rails-admin"を使用した。そのときの導入の流れを記述する。 以下のQiitaを参考にGemを選んだ。
Gemのインストール
公式のGithubに従ってインストールしていきます。
https://github.com/railsadminteam/rails_admin
手順
Gemfileに追記する :
gem 'rails_admin', ['>= 3.0.0.rc', '< 4']bundle installrails g rails_admin:install管理画面にあてるURLを聞かれるので、/adminで良ければ、そのままenter
/adminにアクセス
以上で管理画面が表示されるはずです。本来であれば管理者のみがアクセスできるように制限した方が良いですが、今回は導入して問題を作成できるかが目的だったのでカットします。
触ってみるとわかりますが、作成したモデルについて既に同期してあり、新規作成やテーブルに格納されているデータの編集などができます。
問題と回答を作成してみる
問題を格納するQuestionモデルと、回答を格納するChoiceモデルをすでに作成しているので、管理画面から作成できるか使ってみる。


簡単に作成できた。QuestionモデルとChoiceモデルは関連付け(belong_toとhas_many)されているので、問題の編集ページに回答の追加の項目があり使いやすい。
まとめ
Gem "rails-admin"を使用し、管理画面でクイズの問題と回答が追加できる機能を実装した。管理画面のアクセス制限なども進めていきたいと思う。 記事に関することで質問や何か聞きたいことがコメントまで。お気軽にどうぞ。
参考資料
【将棋】【Python】seleniumを使って、棋譜のURLをスクレイピングする
はじめに
将棋のデータ分析をしてみたくて、Pythonのスクレイピングを学んでみた。目標は、棋士の戦法別勝率、同一局面検索、戦型ごとの対局数をグラフ化して流行している戦型を見つける、などができればと考えている。
勉強に使った教材
Python × スクレイピング https://www.youtube.com/playlist?list=PL4Y-mUWLK2t1LehwHVwAqxXTXw5xd-Yq8
スクレイピングに必要なselenium,BeautifulSoup,requestsなどの扱い方がわかりやすく説明されている。
将棋DB2サイトにある棋譜を自動で取得
こちらのサイトはほぼ全てのプロ棋戦の棋譜が載っているので、これを題材に行なった。ソースコードは以下。
from time import sleep from selenium import webdriver from selenium.webdriver.chrome.options import Options import pandas as pd chrome_path = '/Users/○○○○○○○/chromedriver' options = Options() options.add_argument('--incognito') #URLにアクセス driver = webdriver.Chrome(executable_path=chrome_path, options=options) url = 'https://shogidb2.com/latest/page/{}' d_list = [] #1ページ目から5ページまでを取得する for i in range(1,6): target_url = url.format(i) driver.get(target_url) sleep(2) elements = driver.find_elements_by_class_name('list-group-item') #list-group-item内の取得したい要素を取ってくる for element in elements: tournament = element.find_element_by_tag_name('p').text first_and_second = element.find_elements_by_class_name('h5') first_move = first_and_second[0].text second_move = first_and_second[1].text tactics = element.find_element_by_class_name('text-right').text kihu_url = element.get_attribute('href') #リストに格納する d = { '先手': first_move, '後手': second_move, '棋戦': tournament, '戦法': tactics, 'url': kihu_url } d_list.append(d) sleep(2) #csvファイルにするためにpandasを使用 df = pd.DataFrame(d_list) df.to_csv('○○○○○○○.csv') #ブラウザを閉じる driver.quit()
これを実行して生成されたcsvファイルがこちら。

課題
まとめ
seleniumを使って、棋譜のURLを自動で取得することができた。まだ上記であげた課題が残るので、次回以降改善していきたいと思う。 記事に関することで質問や何か聞きたいことがコメント or TwitterのDMまで。お気軽にどうぞ。 https://twitter.com/atsu__shogi
【Rails】MVC(モデル/ビュー/コントローラ)の関係を理解する
MVCとは、model,view,controllerの頭文字を取ったものです。RailsでWebアプリケーションを作るときに大切な概念です。今日はMVC(モデル/ビュー/コントローラ)の関係を理解する記事を書いていきます。
そんな方におすすめの記事です。
MVC(モデル/ビュー/コントローラ)の関係
MVCの関係を図に表すと以下のようになります。
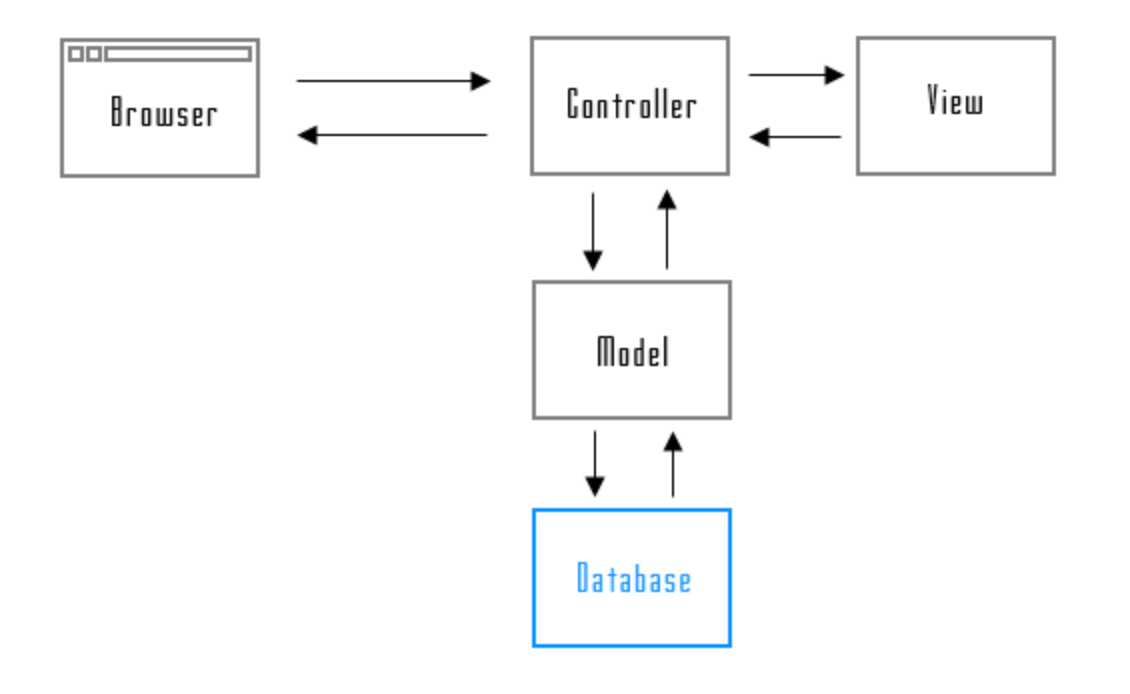
画像引用元:https://www.javadrive.jp/rails/ini/index7.html
Browser:ユーザーが閲覧する部分
Model:データを扱う部分
View:ユーザーが見える結果を扱う部分
Controller:Browserからのリクエストを処理して、ビューとモデルの連携をする部分
Database:データが格納されている場所
この図のサイクルをぐるぐると回して、Webアプリの機能を実装しています。
コントローラーとルーティングの関係
上記では、Controller:Browserからのリクエストを処理して、と記述しました。 具体的には、ルーティングが、Browserからのリクエストを処理する役割を担っています。
Browserからのリクエストを処理する流れは以下になります。
- ユーザーからのリクエストがURLとして届く
- そのURLをもとに、routes.rbに記述されたコードを参照する
- 参照したルーティングに割り当てられた、コントローラのアクション(indexとかnewとか)を呼び出す
- アクションに書かれた処理を実行する
- ブラウザに結果が返される
これがコントローラーとルーティングの関係です。
モデルは、データを参照したり、格納したいときに使う
コントローラのアクションにて、データを参照したり、格納したいときはデータベースとのやりとりが発生するので、モデルを使うことになります。
Railsでは、データベースにテーブル(usersとかboardsとか)が用意されているので、「usersテーブルのid:3のデータを取ってきて!」とか、「id:5にデータを格納して!」と処理していくわけですね。
ビューは、取得したデータを使ってHTMLに変換する
コントローラのアクションにて、データを変数に代入した後(データを扱わない場合もある)は、その変数を使ってブラウザに表示したい画面を記述していきます。
たくさんのビューを用意して、どのビューを表示させたいのか指定するのもコントローラーの役割です。
これで、「ユーザーからのリクエストを処理してその結果を返す」という流れができています。
まとめ
Browser:ユーザーが閲覧する部分
Model:データを扱う部分
View:ユーザーが見える結果を扱う部分
Controller:Browserからのリクエストを処理して、ビューとモデルの連携をする部分
Database:データが格納されている場所
これらを駆使して、Webアプリケーションができていることがわかったかと思います。
MVC(モデル/ビュー/コントローラ)の関係を理解することができたでしょうか?
この記事の説明がわかりやすかった!ここ間違ってるよ!次こんな記事を書いて欲しい!などあればコメント、DMよろしくお願いします。LGTMもぜひ。
Ruby on Railsを中心に「なんとなくの理解で使っているもの」を取り上げて解説しています。そのほかの記事もぜひご覧ください。
ほかの記事
Twitterもやってますので、フォローしていただけたらうれしいです。 卓球、心理学、哲学、Webサービス、好きな音楽、カメラ、登山、ランニング、読んだ本など何でもつぶやいてます。 https://twitter.com/atsushi101011
【Ruby】「ゲッター」と「セッター」とはなんぞや?
Rubyにおける「ゲッター」と「セッター」について解説します。
インスタンス変数を使用するときに出てくるキーワードですね。
「ゲッター」は、インスタンス変数をクラス内から参照するメソッド
ゲッターとは、インスタンス変数をクラス内から参照するメソッドです。コード例は以下のようになります。
Class User
def name
@name
end
end
クラス内にメソッドを作ったあと、user.nameを使えるかというと、以下のようにエラーになってしまいます。
> user = User.new("Tom")
=> #<User:0x00007fd88d1074e0 @name="Tom">
>user.name
=> NoMethodError (undefined method `name' for #<User:0x00007fd88e0707b0 @name="Tom">)
インスタンス変数を参照することはできますが、値がまだ入っていないからですね。こちらのエラーを解消するために、セッターを使っていきます。
「セッター」は、インスタンス変数に値を代入するメソッド
インスタンス変数に値を代入するメソッドを「セッター」と言います。コード例は以下です。
Class User
def name=(name) #セッター
@name = name
end
def name #ゲッター
@name
end
end
先程のエラーは、nameメソッドに対してエラーが出ていましたが、今回はどうでしょうか。
>user = User.new("Tom")
=> #<User:0x00007fd88d1074e0 @name="Tom">
>user.name
=> "Tom"
ゲッターとセッター両方を使うことで、インスタンス変数を使えることができました。インスタンス変数は、参照して値を代入して使うことができます。
3種類のアクセスメソッドを使って、「ゲッター」や「セッター」を簡単に定義する
attr_reader(ゲッター)
attr_writer(セッター)
attr_accessor(ゲッターとセッター)
ゲッターやセッターを定義するために、3種類のアクセスメソッドというものが用意されています。今回は「ゲッター」と「セッター」についての記事なので割愛しますが、ぜひ使い方を調べてみてください。
この記事の説明がわかりやすかった!ここ間違ってるよ!次こんな記事を書いて欲しい!などあればコメント、DMよろしくお願いします。LGTMもぜひ。
Ruby on Railsを中心に「なんとなくの理解で使っているもの」を取り上げて解説しています。そのほかの記事もぜひご覧ください。
ほかの記事
Twitterもやってますので、フォローしていただけたらうれしいです。 卓球、心理学、哲学、Webサービス、好きな音楽、カメラ、登山、ランニング、読んだ本など何でもつぶやいてます。 https://twitter.com/atsushi101011
nilガードの書き方と、使用するメリットについて
Rubyでよく出てくるキーワードのひとつ「nilガード」
Railsチュートリアルでも出てくる概念なので、名前は知っているという方も多いと思います。
今日はnilガードの書き方と、使用するメリットについて記事を書いていきます。
上記のような方々にお読みいただけるとうれしいです。
nilガードの説明と書き方
まずnilガードの説明をします。以下のような書き方をします。
number ||= 10 #①
このコードの意味は、「もしもnumberがあればnumberを返す、nilかfalseであれば10を代入した上でnumberを返す」という意味になります。
また、①と②は同じ動きをします。
number || (number = 10) #②
「左辺があれば左辺を返し、なければ右辺を返す」のが、nilガードです。
例えばこんな感じです。
> a ||= 10 #aはnilなので、aに10を代入してaを返します => 10 > a ||= 20 #a = 10なので、そのまま左辺の10を返します。 => 10
nilガードの書き方がわかったでしょうか。
次にnilガードを使用するメリットについて書いていきます。
メリット①nilを返したことで発生するエラーを防げる
たとえば、aを戻り値で返すコードがあるとします。
return a
ここでaがnilであると、「戻り値がnilだから返す値がないよ!」というエラーが出ます。ほかにも、nilを返してはいけないところでnilを返す可能性があると、エラーが出てしまいます。
ここでnilガードを使います。
return a ||= []
aがあればaを返し、aがなければ[ ]を返します。
nilガードは名前の通り「nilをガードする」役割なので、nilを返してはエラーが出てしまう!というときに役立ちます。
メリット②リファクタリングできる
以下の2つのコードは同じ意味になります。
if a != nil a = a else a = 10 end
a ||= 10
nilなのかどうか?でif文を使ってしまうと、コードが長くなってしまいます。
nilガードを使うことでリファクタリングすることができます。
まとめ
・nilガードの書き方「左辺があれば左辺を返し、なければ右辺を返す」
number ||= 10
nilガードを使うメリットは
nilガードの書き方と、使用するメリットについて解説しました。どんどんnilガードを使って理解を深めていきましょう。
この記事の説明がわかりやすかった!ここ間違ってるよ!次こんな記事を書いて欲しい!などあればコメント、DMよろしくお願いします。LGTMもぜひ。
Ruby on Railsを中心に「なんとなくの理解で使っているもの」を取り上げて解説しています。そのほかの記事もぜひご覧ください。
ほかの記事
Twitterもやってますので、フォローしていただけたらうれしいです。 卓球、心理学、哲学、Webサービス、好きな音楽、カメラ、登山、ランニング、読んだ本など何でもつぶやいてます。 https://twitter.com/atsushi101011
Rubyのハッシュとシンボル、キーの関係について、わかりやすく解説する
曖昧な理解になってしまいがちな「ハッシュ」と「シンボル」について、解説していきます。 Rubyを勉強し始めた時は全然わからなかった。。
この記事を通して
ハッシュとキーの関係がわかる
シンボルの使い方がわかる
ようになれば幸いです。
ハッシュは、「関連付いた名前をつけて、データを格納したいとき」に使う
数学のテストがあって、データが点数順に並んでいるとします。
score = [56,43,55,78,79,66,73,90,45,65,43,25]
ここで、taro君の点数を知ろうとしたとき「score」というデータだけではわかりませんよね。「name」という、データに関連付いた名前が必要になってきます。
ここで、ハッシュの登場です。 ハッシュとは、「関連付いた名前をつけて、データを格納したいとき」に使うことができます。
{ :name => score } #今回の例であれば { :taro => 56 }
このような形でハッシュを作ることができます。これでtaro君の点数を知ることができるようになりました。
データに関連付いた名前のことを「キー」と呼ぶ
「:taro」の部分をキーと呼びます。キー(データに関連付いた名前)とデータのセットであるハッシュを格納するわけですね。
キーは、文字列、時間、数字など、任意のオブジェクトを使うことできますが、「シンボル」と呼ばれる、コロンではじまる識別子をよく使います。(例 => :太郎)
またキーとデータの間の区切りにコロンを使えば、シンボル名の頭のコロンを省略することができます。
# ①文字列 "taro" => 56 # ②シンボル :taro => 56 # ③一番良く使う表記 taro : 56 ①、②、③は同じ意味になります
シンボルは「何かしらの名前を表す存在だよ」ということを示しています。
「:taro」になったり、「taro:」になったりして、コロンに惑わされると思うのですが、①、②、③が同じであることがわかれば安心かと思います。
まとめ
以上、ハッシュとシンボル、キーの関係について、解説していきました。
* 「ハッシュ」・・・「関連付いた名前をつけて、データを格納したいとき」に使う * 「キー」・・・データに関連付いた名前 * 「シンボル」・・・コロンではじまる識別子を使ったキー
この3点をおさえていきましょう。
この記事の説明がわかりやすかった!ここ間違ってるよ!次こんな記事を書いて欲しい!などあればコメント、DMよろしくお願いします。LGTMもぜひ。
Twitterもやってますので、フォローしていただけたらうれしいです。 卓球、心理学、哲学、Webサービス、好きな音楽、カメラ、登山、ランニング、読んだ本などなんでもつぶやいてます。
git fetchとmerge、pullの関係をわかりやすく説明する【Gitコマンド解説②】
Gitコマンドはたくさんありますよね。git addとcommit,pushなどは良く使うコマンドだからわかるけど、
fetch、merge、pullになると「どういう意味かわからない...」という方は多いのではないでしょうか。
git fetch git merge git pull
今日は3つのGitコマンドについて、できるだけわかりやすく解説していきます。
そもそもgit addとcommit,pushがわからない!という方は、こちらの記事を読んでくださいね。
↓↓↓
git addとcommit、pushの関係をわかりやすく説明する【Gitコマンド解説①】
git pullは、fetchとmergeの両方を組み合わせたコマンド
上記の記事で、ローカルリポジトリの内容をリモートリポジトリに送信(アップロード)することを「push」と呼びましたね。
反対に、リモートリポジトリからローカルリポジトリを更新することを「pull」と呼びます。
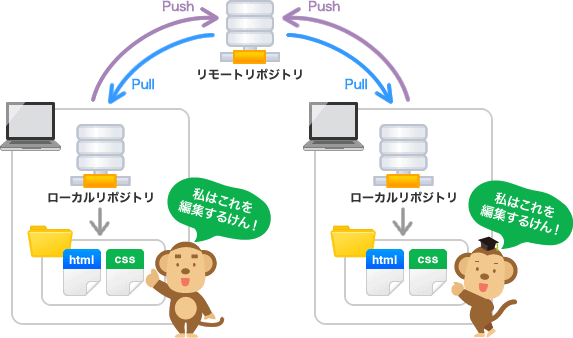 画像引用:https://backlog.com/ja/git-tutorial/intro/02/
画像引用:https://backlog.com/ja/git-tutorial/intro/02/
例えば、A君とB君がチーム開発しているとします。A君が更新したファイルをBくんにも反映させたいです。
これを実現する流れは、以下のようになります。
1.A君がローカルリポジトリの内容をリモートリポジトリに送信(アップロード)する(push)
2.B君がリモートリポジトリからローカルリポジトリを更新する(pull)
これがpullの役割です。見出しには「git pullは、fetchとmergeの両方を組み合わせたコマンド」と書きました。以下のような関係式が成り立ちます。
pull = fetch + merge
ここでfetchとmergeの意味がわからない!となったと思うので、それぞれ解説していきます。
git fetchでリモートからローカルに持ってきて、git mergeでローカルを更新する
リモートリポジトリから最新情報をローカルリポジトリに持ってくることを「fetch」と呼びます。また、fetchを使ってローカルに持ってきた最新情報を更新することを「merge」と呼びます。mergeには「統合する、融合させる」という意味があります。
さきほどの関係式をわかりやすくすると、こんな感じです。
pull(リモートから持ってきて更新) = fetch(リモートから持ってくる) + merge(ローカルを更新)
「pullとfetchなにが違うの?」と思ったかもしれません。
pullとfetchの違いは、実際にファイルを更新するかどうかの違いです。mergeをしないとローカルが更新されないわけですね。
※個人開発の場合でも、ブランチを分けて作業することが多いと思います。ブランチで作業していた内容を統合させたいときにmergeコマンドを使うことになります。リモートリポジトリを共有するチーム開発だけで使うコマンドじゃないってことです。
まとめ
1.リモートリポジトリから最新情報をローカルリポジトリに持ってくることを**「fetch」**と呼ぶ 2.fetchを使ってローカルに持ってきた最新情報を更新することを**「merge」**と呼ぶ 3.**「pull」**はmergeとfetchをまとめて行うコマンド<br><br>
これで、git fetchとmerge、pullの関係について理解が深まったかと思います。
次回は、git clone、log、branch、statusあたりのコマンドについて解説します。
この記事の説明がわかりやすかった!ここ間違ってるよ!次こんな記事を書いて欲しい!などあればコメント、DMよろしくお願いします。LGTMもぜひ。
Twitterもやってますので、フォローしていただけたらうれしいです。 卓球、心理学、哲学、Webサービス、好きな音楽、カメラ、登山、ランニング、読んだ本などなんでもつぶやいてます。